前言
在上篇《大型互联网应用的数据缓存架构设计和客户实践》中,我们探讨了大规模缓存服务的架构设计和客户实践,那这篇我们来说说数据库的分库分表,跟很多客户的数据库和开发团队对话的时候,总是反复提及,我想在大型交易系统中关系数据库的性能线性扩展至关重要;譬如刚刚结束的 2019年的双11,黑五年度大促,人为创造的购物狂欢的背后,是技术人提前半年甚至一年的 Gameday 准备,大促期间彻夜无眠的默默守护,其中最让人揪心和担心的就是后台承担落地业务成绩的关系数据库。
自从1979年诞生第一个商业版关系数据库产品以来,它的设计范式,ACID 的事务特性,SQL 查询语言等等,都经受住了时间的考验,到目前依旧是现代互联网应用IT基础设施的基石之一;数十年来,对关系数据库进行扩容并同时保持容错、高性能和较小的爆炸半径(发生故障的影响)一直是数据库管理人员的持续挑战;在2017年AWS的reinvent大会上,《ARC406: Amazon.com Replacing 100s of Oracle DBs with Just 1 DynamoDB》来自亚马逊电商的资深开发人员介绍到,扩展和运维分库分表的关系数据库非常“痛苦”,这项工作,要求有专门的系统和数据库管理员全神贯注的一项劳动密集型型工作;
我们先看看披露出来的亚马逊电商订单分布式工作流系统 Herd 的关系数据库扩展历史,刚开始 3个库还好,过了两年到十几个库,再过了几年增长到100+ 个库,在有一年的 Prime day 大促的时候,该系统的横向拆分出来的数据库最多扩大到 1000个;想想头就大,扩展一个新的数据库,要准备机器,创建数据库秘钥,创建表,优化数据库参数,创建新的服务,获取链接信息,更新应用配置,准备负载均衡,定义新的报警,功能测试,性能测试,最后还要对应用尽量透明无缝进行分片;还没算上运维代价,系统补丁,数据库补丁和升级,索引重构,问题排查(比如为什么有的库比较慢?),硬件故障,这的确是一盘需要“精心照顾”的菜(方案)。

亚马逊电商案例表明分库分表可以解决传统关系数据库扩展性问题但同时也带来了痛苦的应用改造、运维、排错等繁重容易出错的大量工作负担, 我们还有其他选择吗?那我们回归初心,现代化应用程序对底层支撑服务的诉求是什么?亚马逊全球首席技术官 Werner 博士在他的博客中总结了现代化应用程序需要关注三点基础设施的的特性:
-
从小规模起步,到大规模增长,数据库等基础设施不应该限制业务发展速度。
-
在大型系统中,故障属于客观常态,而非异常;发生组件或系统故障时,客户的应用有能力做隔离。
-
故障的爆炸半径要小,恢复时间要短;没有人希望单一的系统故障对他们的业务产生巨大影响。
应用视角看数据库扩展和性能优化场景
- 读写分离
- 按业务领域定义边界,微服务架构再到分库
- 分表
1.读写分离
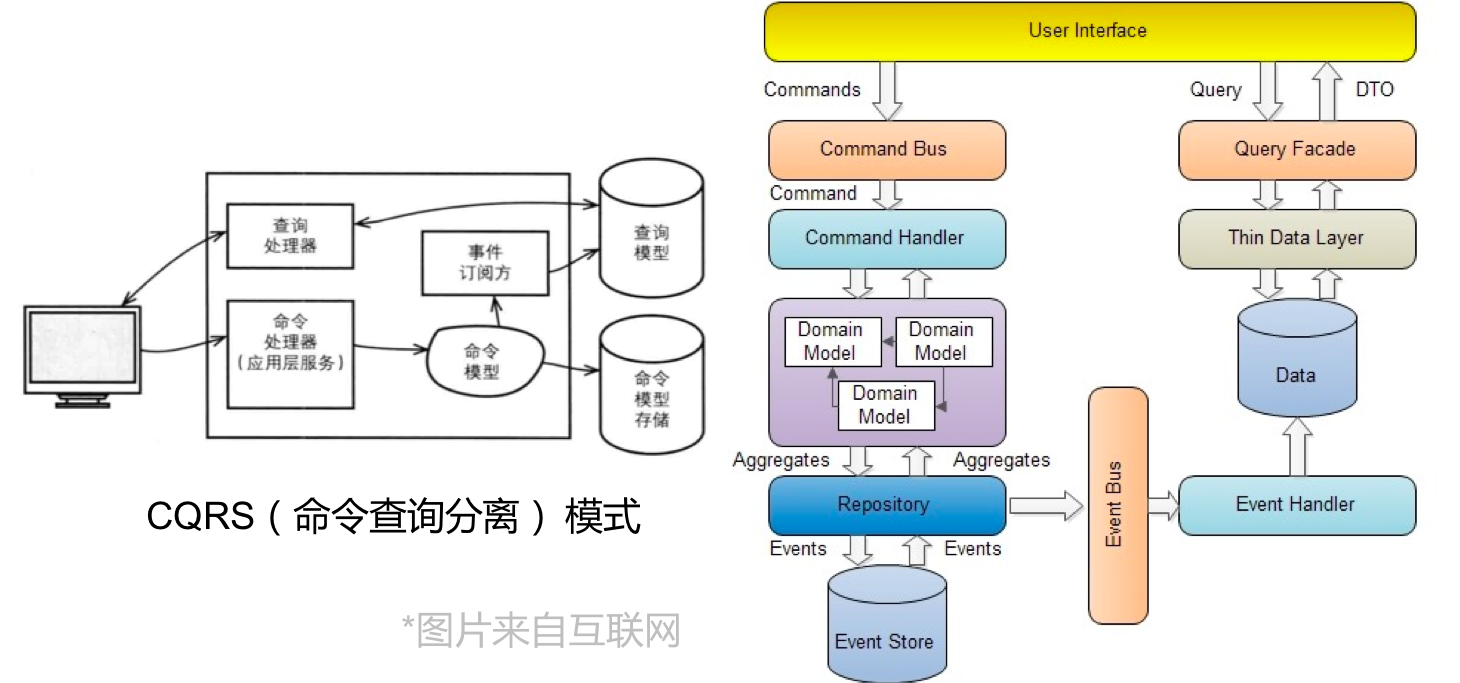
读写分离,是使用最广泛的优化策略之一;为了满足主库的写性能的要求,尽量将读的请求从主库剥离开来,同时,利用数据库的主从策略,可以提供一个主库的故障自动切换,切换时间取决于判断故障的时间,前端应用如何无感切换,数据同步延迟等;在下面的分库环节,我们再继续深入下微服务架构体系下常见的数据模式 CQRS(Command QueryResponsibility Segregation)命令查询分离,是读写分离的进一步演进;

2.按业务领域定义边界,微服务架构再到分库
在微服务架构下,实践中每个微服务都是按业务领域划分,自治的服务,每个服务都有自身的数据库,服务跟服务之间通过接口通信,不允许直接访问对方的数据库;对比把所有的业务的数据表放到一个数据库中,分库的思路,将不同业务组件的数据表拆分出来放到独立的数据库中;原来一个单库的读写请求,就会扩展到对多个数据库实例进行读写;

好处很多,可以按业务组件的数据访问特性来优化各自的数据库性能,业务组件之间关系解耦互相独立开发测试发布;缺点是,相对于单库系统,整体应用系统的复杂度提升,跨多个数据库的分布式事务和查询需要额外的中间件支撑;对于跨多个业务单元的数据分析或查询需求,可以利用上文提到的 CQRS 模式,利用CDC(Change Data Capture)管道将数据实时汇总到数据湖进行加工处理之后满足业务的查询和分析需求;对于跨多库的分布式事务,社区中客户常用的中间件一般支持可选择的数据一致性配置,比如利用 2PC/3PC(两阶段提交或三阶段提交)实现分布式强一致性,或者尽最大努力的最终一致性,还有一些 NewSQL 的方案,利用 Raft 或 Paxos 实现分布式系统的一致性问题,通常不建议客户选择 2PC/3PC 算法,系统性能影响明显,更多考虑事件溯源通过业务对象全局 ID 跟踪判断整个跨业务单元的数据一致性问题,对于有问题的事务采取补偿或回滚操作,最理想的是,应用层不感知如此复杂的分布式事务处理。
3.分表
对于一张表的条目过多影响性能的情况下,分表即将多行记录水平切分到多个数据库进行分表存储,或者将一张表中多列垂直拆分开来,把某些大容量,不常用的列移除出去;数据表的横向拆分是最复杂的场景,拆分规则通常可以自定义,比如按用户地理区域独立存储和处理,随机通过哈希函数将记录保存到不同的数据库中,或者带时间维度的Snowflake雪花分片算法(在扩容的时候无需数据迁移,因为根据时间可以切换到新的扩容后的分片逻辑);如果真的要水平拆分数据表,建议从业务角度来设定规则,而不完全从技术出发;
通常分表和分库是同时进行的,这样带来的技术挑战有:分布式事务问题,跨多个数据库节点聚合,节点扩容后的分片数据是否要迁移等等。大家可以阅读AWS 博客了解更多分库分表的业务逻辑设计:Shardingwith Amazon Relational Database Service(http://rrd.me/fjPeL )

读写分离及分库分表解决方案
无论是读写分离还是分库分表,核心诉求就是随着业务发展,期望数据库能够按需扩展,因此,在应用和数据库层之间加一层无状态代理来处理复杂的后端数据库连接池管理,应用无感的故障切换以及自动升级,一开始架构设计的时候,就应该考虑;
- 云托管的数据库代理服务
- 开源的数据库代理组件
1.云托管的数据库代理服务
亚马逊 AWS 在 2019年刚刚结束的reinvent大会终于发布了一个托管的数据库访问的代理服务 RDS Proxy(http://rrd.me/fjNYB)目前处于公开预览阶段,预览功能主要集中在连接池和安全 IAM 认证,大家可以注册预览版体验;另外,亚马逊 AWS 的 Marketplace 上也有非常多的第三方商业版的数据库代理服务解决方案,比如 Heimdall Data Premium Edition 已经在亚马逊中国 Marketplace 上线 “对应用完全透明的数据库代理。可以提升现有数据库的SQL性能和稳定性(例如Amazon RDS、Aurora和Redshift;SQL Server、MySQL、Postgres等)。而且可以部署在一个单独的EC2代理层上,不需要更改应用程序。” 特色功能支持自动缓存数据和自动缓存数据失效,对企业应用透明,应用无需做任何修改,大家可以去试用;

2.开源的数据库代理组件
开源社区有很多优秀的数据库代理中间件,下面列举几个常见和活跃的产品,排名不分先后:
2.1.ProxySQL: https://github.com/sysown/proxysql
项目获得 3400 颗星,文档丰富,网上教程很多;特色高性能,跨平台,不仅仅是请求转发,ProxySQL 是理解 MySQL 协议的应用层 SQL 负载均衡,支持权重的目标库转发策略;支持读写分离,故障切换,连接池(连接池大小限制,按用户的连接池大小限制,超时,连接复用等等);支持分库分表,基于 IP和端口,以及 Query 的分库分表策略等;很多客户配合 AWS RDS或 Aurora 使用,可以参考一篇博客了解详情:Supercharge your Amazon RDS for MySQLdeployment with ProxySQL and Percona Monitoring and Management ( http://rrd.me/fjNKp )

2.2.MaxScale: https://github.com/mariadb-corporation/MaxScale
项目获得 955颗星,文档丰富;基于 C/C++ 实现;SQL 负载均衡能力和ProxySQL 类似,基于 IP/端口,Query 等 SQL 分发路由,支持读写分离,故障切换,仅支持基于 Schema 的分库,不支持分表;Airbnb 在 AWS 2017年reinvent 大会分享的《Airbnb Runs on Aurora》主题里面透露,该技术团队采用的就是定制版的 MaxScale 作为数据库访问代理,该代理顺利协助 Airbnb 团队从 AmazonRDS for MySQL 无缝升级到了 Amazon Aurora,应用无感知;ProxySQL 和 MaxScale 有一个功能对比,大家可以参考:https://www.proxysql.com/compare

2.3.Vitess: https://vitess.io/
项目获得 9200颗星,2010年由 YouTube 团队创建用来解决 MySQL 扩展性问题,2018年加入 CNCF(CloudNative Computing Foundation)成为第8个项目,并于 2019年11月正式毕业;社区非常活跃,文档丰富,大量互联网客户案例。支持动态分库分表,连接池管理,安全防火墙(坏味道 SQL 屏蔽,自动关闭需要长时间才返回的请求,基于用户数据表级别访问控制等)。

2.4.国内互联网公司开源项目
Gaea(https://github.com/XiaoMi/Gaea):小米中国区电商研发部门参考 MyCat、Kingshard 和 Vitess 研发的基于 MySQL 协议的数据库中间件代理,项目获得1300颗星,广泛应用于小米商城,包括订单、社区、活动等多个业务。
Ctrip DAL(https://github.com/ctripcorp/dal):携程框架部门开发的数据库访问框架,支持数据库水平扩展,支持代码(Java,C#)自动生成,携程内部2000多个应用在使用 DAL 框架。
DBProxy(https://github.com/Meituan-Dianping/DBProxy):美团点评公司技术工程部 DBA团队(北京)开发维护,它在奇虎 360公司开源的 Atlas基础上,修改了部分 bug,并且添加了很多特性。“目前 DBProxy 在美团点评广泛应用,包括美团支付、酒店旅游、外卖、团购等产品线,公司内部对DBProxy的开发全面转到github上,开源和内部使用保持一致。目前只支持MySQL(Percona)5.5和5.6”。
现代分布式数据库架构创新
我们前面列举了很多分库分表做的非常成功的案例,读者也发现,有非常多的优秀的简化分库分表的中间件,在作出分库分表决定之前,我们是否再探索下有没有更好的方案架构?云计算时代的关系数据库的创新,计算和存储分离的组件化、微服务架构,构建的新型分布式关系数据库架构极大提升了原本开源关系数据库的性能和扩展性。
2019 年 10月15日,AWS 布道师 Jeff Barr 在官方博客发布标题为《迁移完成–亚马逊的消费者业务部关闭最后的Oracle数据库》,我们可以看到亚马逊消费者业务部门包括Alexa,Amazon Prime,Amazon Fresh, Kindle,Twitch,AdTech,付款,退货,市场,订购和零售系统等等 100多个团队,抛弃了传统的分库分表的 Oracle 关系数据库,转向主要两个重要的分布式数据库 Amazon DynamoDB 和 Amazon Aurora。就比如本文开头提到的订单分布式工作流系统,从分库分表直接重构到以一张 Amazon DynamoDB 表为核心的新的数据处理方式,从而使得数据库管理员摆脱无差异的分库分表运维工作:

- NewSQL 计算存储分离组件化架构:从Amazon Dynamo 说起
- Amazon Aurora与 PingCAP 的TiDB
1.NewSQL 计算存储分离组件化架构:从Amazon Dynamo 说起
2007 年亚马逊全球首席技术官 Werner 博士在他的博客中披露了 Amazon Dynamo 论文的全部内容,从论文中,我们可以看出,1995年创立的亚马逊电商平台在高速发展当中遇到的使用单一传统关系数据库应对所有电商场景的痛点,所以,亚马逊技术团队期望设计一个新型的数据库满足客户“永远在线”的诉求和体验;
Amazon Dynamo 设计了一个点对点(Peer-to-Peer)分布式、可扩展、高可用的数据存储服务,类似的被广泛使用的开源实现有 Apache Cassandra,基于 Google BigTable 论文的 Apache HBase 都有着类似的数据结构,什么样的数据结构呢?如下图所示,跟关系数据库的表设计不一样的地方在于,每张表会有(row key, columnkey),可以说是一种面向高可用优化的列式数据库。

熟悉 Amazon DynamoDB 的同学都会知道,设计 DynamoDB 的表结构最重要的考量就是,从数据访问模式出发,设计表的分区键和排序键,同样的分区键记录会被保存在一起(同一块存储区域),针对列的本地排序键仅能高效查询本分区的数据,要跨多个分区来查询数据,需要创建全局二级索引,该索引同时包括新的分区键和排序键,底层是数据重组之后的一份复制(http://uee.me/cF6Px)
从实现层来说,需要有三大服务组件:对外暴露的接口请求分发,(存储,请求分发)节点增删及健康检查,存储节点的持久化引擎;从论文上来看,当时设计的组件都是基于 Java 来实现的;

如上图所示,Request Router 的实现是一个类似 SEDA(Staged Event DrivenArchitecture)的事件驱动的状态机,该组件接受客户端的读取和写入请求,每个客户端的请求都会在收到该请求的节点上生成一个状态机,该状态机只为该客户端请求服务,比如一个读取请求处理(1)将请求发送到底层的存储节点(2)等待指定的最小数量的副本数据返回(3)如果返回不够指定最小数量的数据副本,则通知客户端请求失败(4)否则,通过数据版本,将最新的数据返回给客户端,还可以包含额外的失败重试逻辑。写入请求是写到一个 Leader 节点,再通过 Leader 节点复制到其他存储节点上去。
单个存储节点的基本组件如下图所示,首先存储节点本身就是一个系统,数据的具体操作需要一个本地的数据操作引擎,论文透露大部分存储节点的引擎使用了Berkeley Database(BDB)Transactional Data Store,当然也可以适配其他的存储引擎;多个存储节点之间通过 Gossip 协议通告节点状态,多个副本通过 Paxos 协议实现主节点的选举,也就是说,写入操作是先在主节点写入再复制到其他副本节点。

2.Amazon Aurora与 PingCAP 的TiDB
从 NoSQL 类型的分布式数据库,我们至少抓住一个关键主题就是,新型数据库的很重要一环就是底层分布式高可用的存储系统创新,回归本篇主题关系数据库,为了更加客观和便于理解,我把 AWS 托管的分布式关系数据库Amazon Aurora 和开源火热的 TiDB 放在一起来看;

TiDB 核心也是三个核心组件,TiKV 服务是基于 RocksDB 单机存储引擎加上 Raft 协议实现分布式可以扩展的存储系统,具体架构可以参考下图,TiKV 进一步把存储分解成 Region 块在多个节点之间进行冗余复制;PingCAP团队的创新点是针对 MySQL 协议,实现了很多 RocksDB 上的优化;多个节点的元数据,状态更新,调度和负载均衡等工作是由 PD(Placement Driver)服务集群负责,PD 集群利用 Raft 做选举,同时仅一个节点来处理所有的操作,其他节点作为高可用副本。

对照亚马逊 Amazon Aurora 数据库,同理实现了一个跨三个可用区 6份数据副本的分布式存储系统,数据库卷逻辑上分为 10GB 单位大小,各个分段都分散在庞大的分布式存储队列中。如果发生某个故障,导致一个分段丢失,单个保护组的修复只需要移动大约10GiB 的数据,几秒钟即可完成;更重要的是,Amazon Aurora 遵循日志即数据,通过只将重做日志记录写入存储层,系统可以将网络的 IOPS 减少一个数据量级;同时将数据库系统中最复杂与关键的功能,备份恢复等等也委托给了存储层服务;

| 一口气说了 Amazon DynamoDB、TiDB 以及 Amazon Aurora 的分布式存储系统,大家应该可以看出分布式高可用的存储系统是现代数据库的核心组件之一;那我们接着来看看对外的服务接口,Amazon Aurora 团队,在MySQL/PostgreSQL 引擎基础之上,将计算和存储做了分离,计算层面改写和优化了原来的 SQL解析,事务和缓存处理,因此和原生的 MySQL 或 PostgreSQL 完全兼容;目前更是支持多主多写,以及跨区域毫秒级数据复制;更多的的技术细节请参考《大咖博客 | Amazon Aurora 冉冉升起:我们是如何设计原生云关系数据库的?》《比MySQL快10倍?这可能是目前AWSAurora最详解读!》 |

而 PingCAP 团队则完全重写了一个兼容 MySQL 协议的处理层组件TiDB,该组件解析 SQL 并负责关系模型数据和底层存储引擎之间的交互,所以要特别关注跟原生 MySQL 兼容性问题,可以参考官方对比文档(http://uee.me/cF7Av)

总结
分库分表是在大规模场景下的一个选择,但不是唯一选型,NewSQL 包括分布式高可用的 NoSQL 数据库比如云托管的 Amazon DynamoDB,开源的Apache Cassandra,MongoDB等,分布式关系数据库引擎如 Amazon Aurora 及开源的 PingCAP 的 TiDB 项目都给到客户更多的选择,最后能针对客户具体应用场景优化,随着客户业务发展而弹性扩展,容错、高可用且零运维才是业务持续运营的长久选择。
